Introduction
This website contains additional information about our paper “Dos and Don'ts of Machine Learning in Computer Security”. In the paper, we identify common pitfalls in the design, implementation, and evaluation of learning-based security systems. Please note that this website is still under construction. However, we will continuously add further information that we find helpful for the community.
Details
With the growing processing power of computing systems and the increasing availability of massive datasets, machine learning algorithms have led to major breakthroughs in many different areas. Despite great potential, machine learning in security is prone to subtle pitfalls that undermine its performance and render learning-based systems potentially unsuitable for security tasks and practical deployment.
In the paper, we look at this problem with critical eyes. First, we identify common pitfalls in the design, implementation, and evaluation of learning-based security systems. We conduct a study of 30 papers from top-tier security conferences within the past 10 years, confirming that these pitfalls are widespread in the current security literature. In an empirical analysis, we further demonstrate how individual pitfalls can lead to unrealistic performance and interpretations, obstructing the understanding of the security problem at hand. As a remedy, we propose actionable recommendations to support researchers in avoiding or mitigating the pitfalls where possible. Furthermore, we identify open problems when applying machine learning in security and provide directions for further research.
Important Note
Please note that our paper should not be interpreted as a finger-pointing exercise. On the contrary, it is a reflective effort that shows how subtle pitfalls, affecting our own research also, have a negative impact on actual progress, and how we—as a community—can mitigate them adequately.Pitfalls & Recommendations
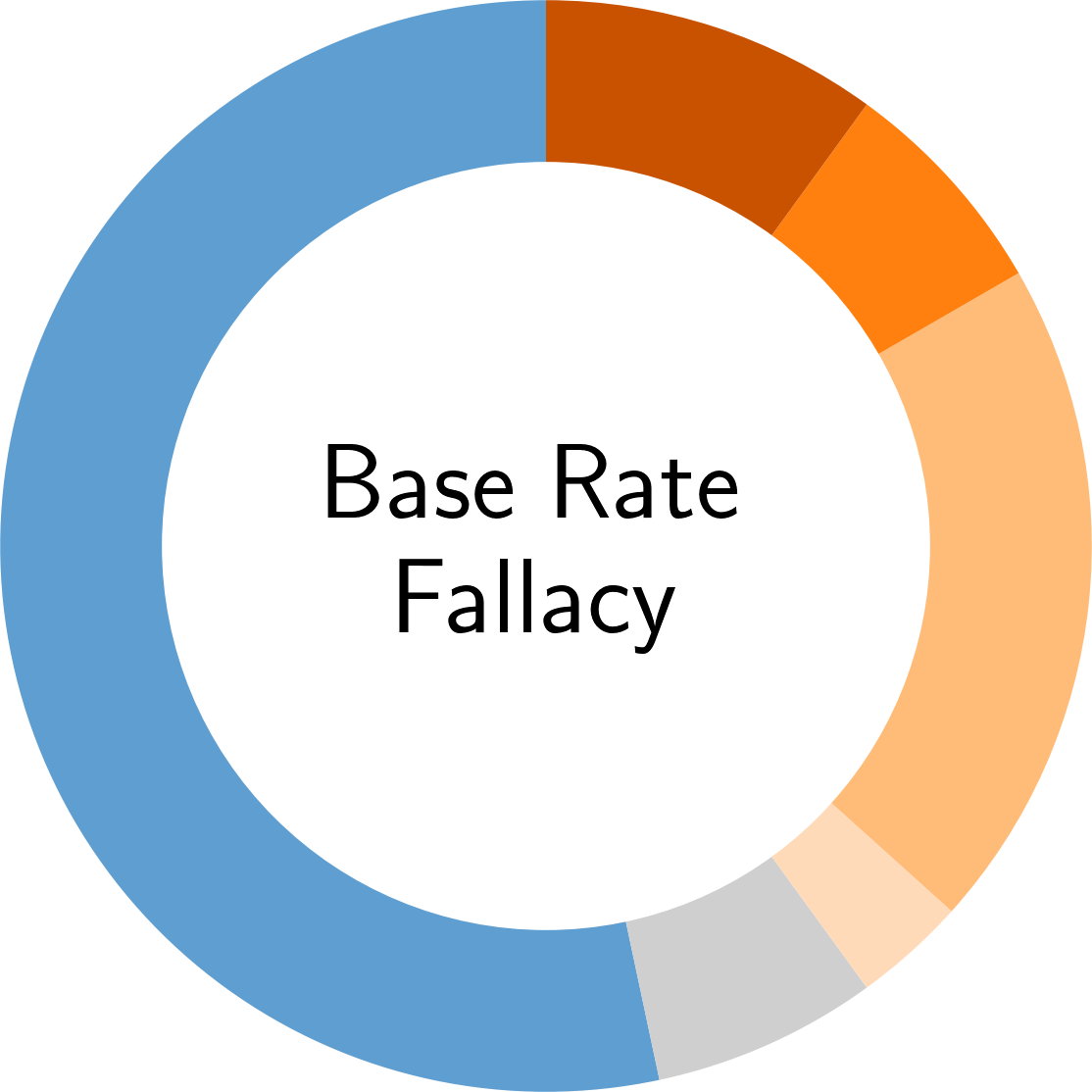
In the following, you find an overview of the identified pitfalls and their prevalence in the reviewed secury literature. To get details of each pitfall, please click on the corresponding symbol:
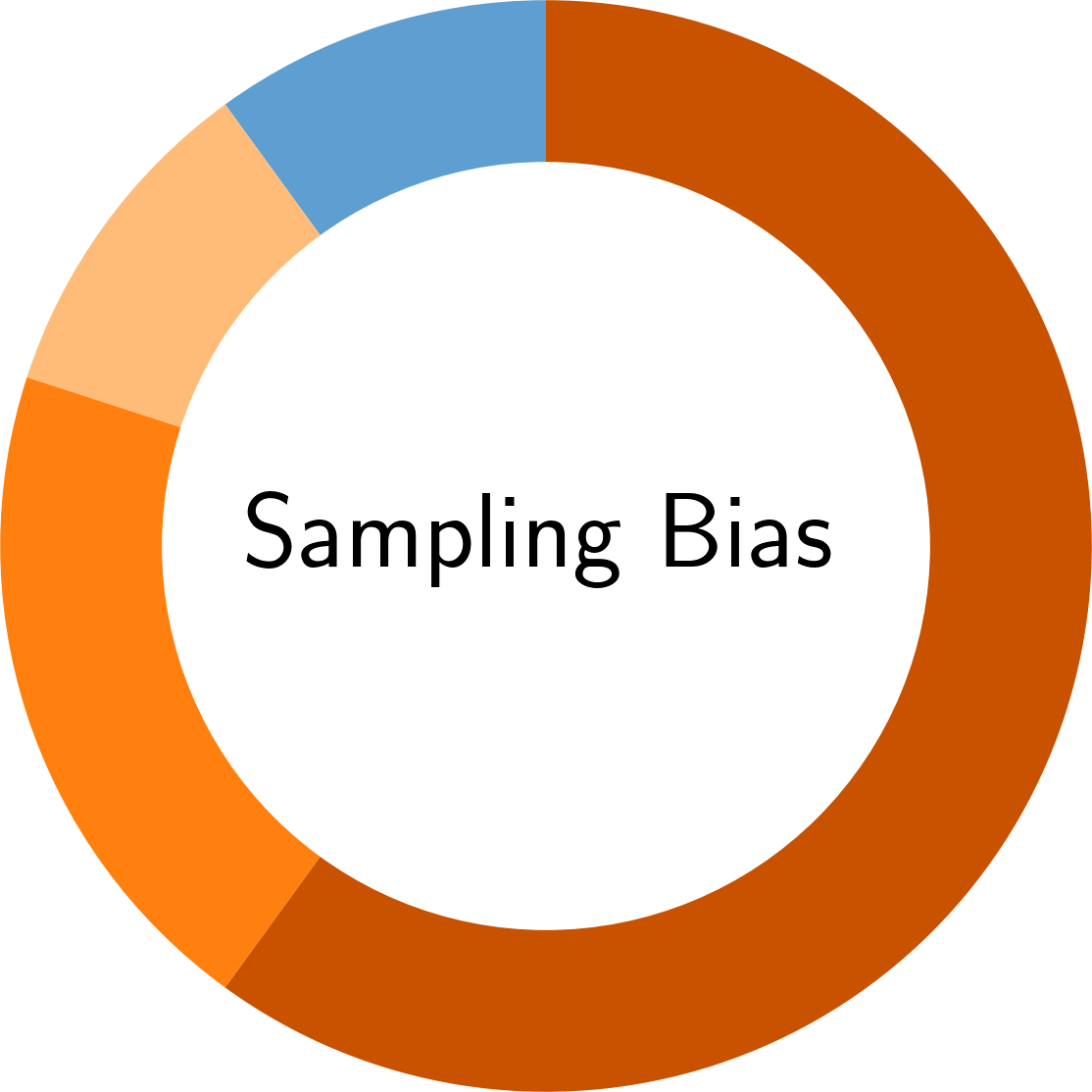
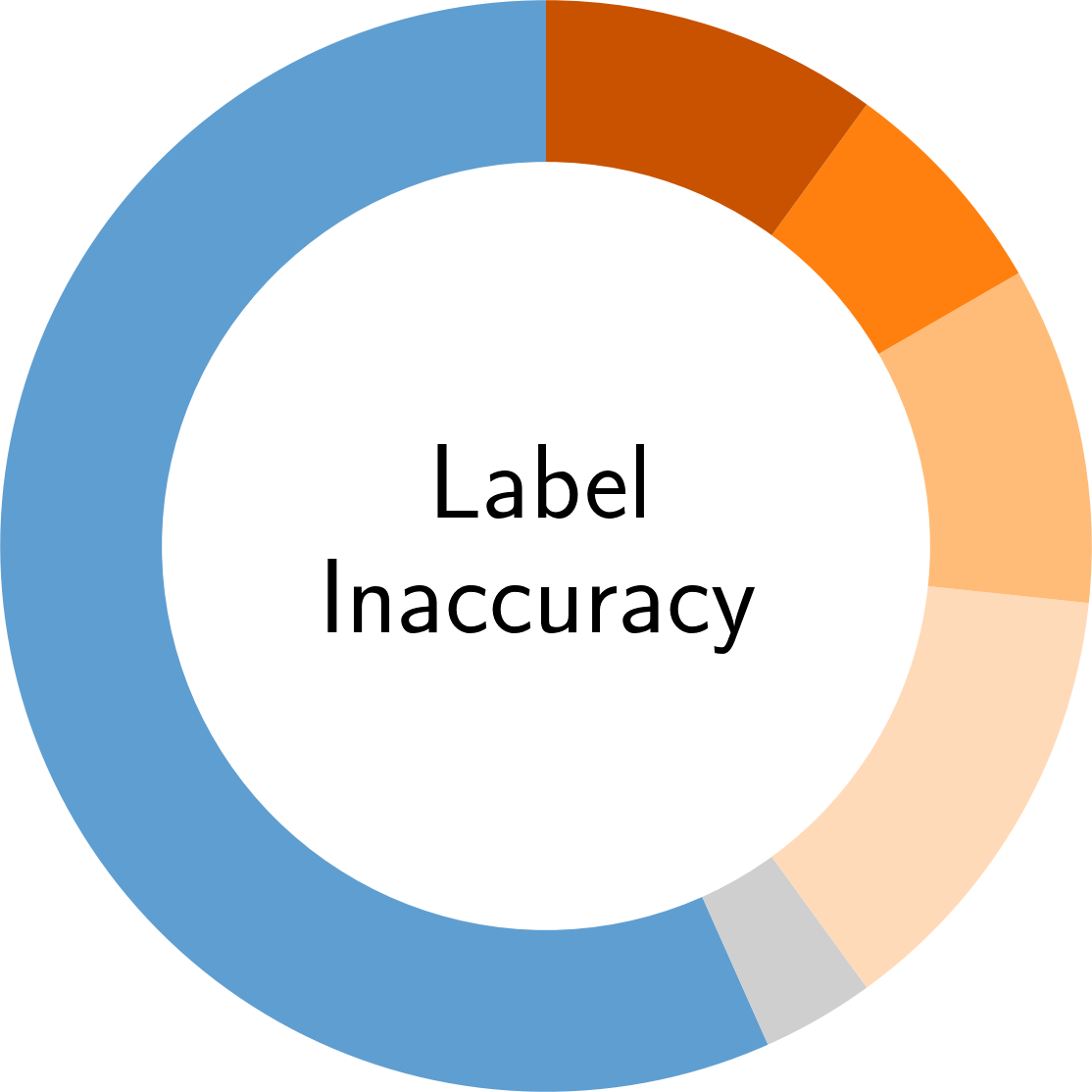


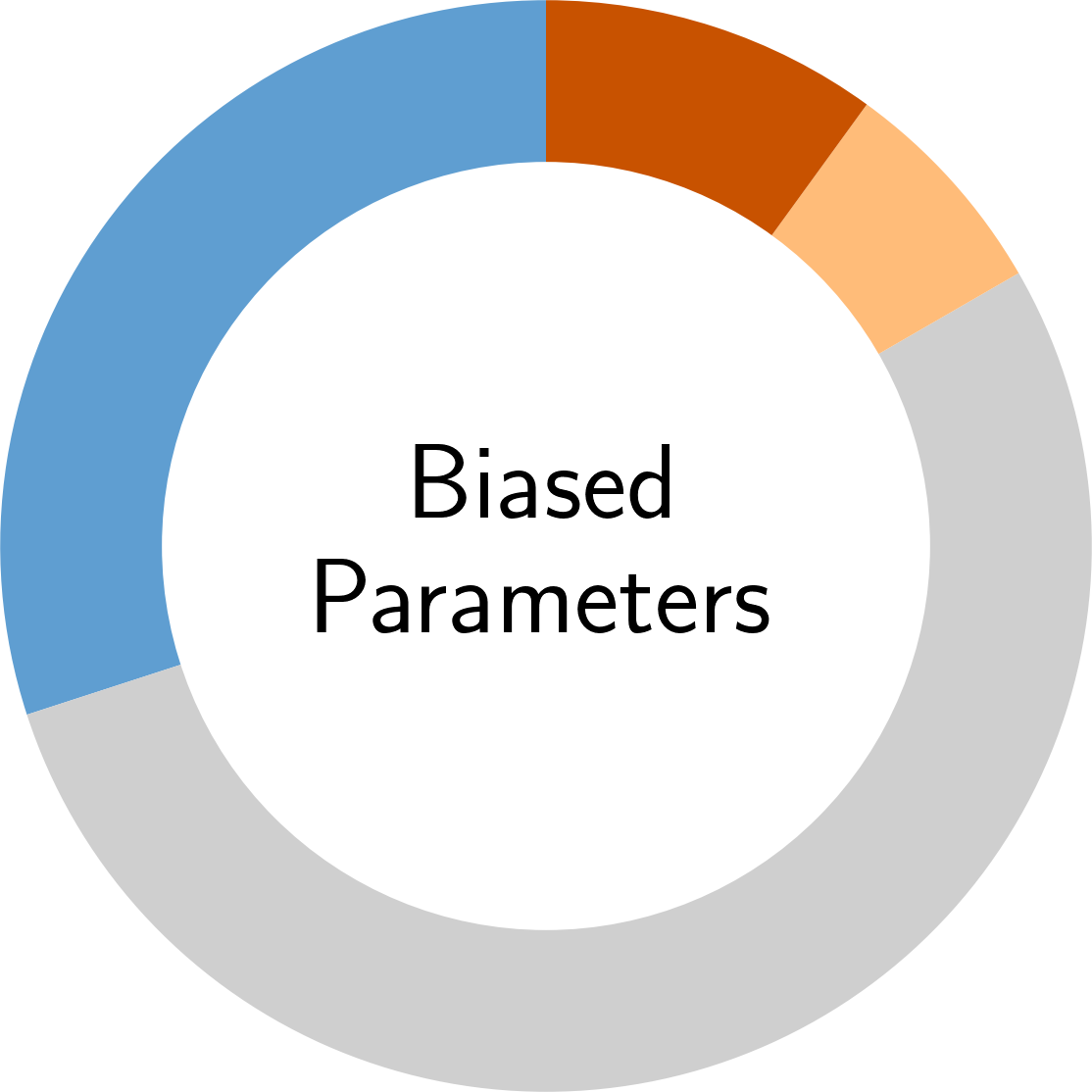

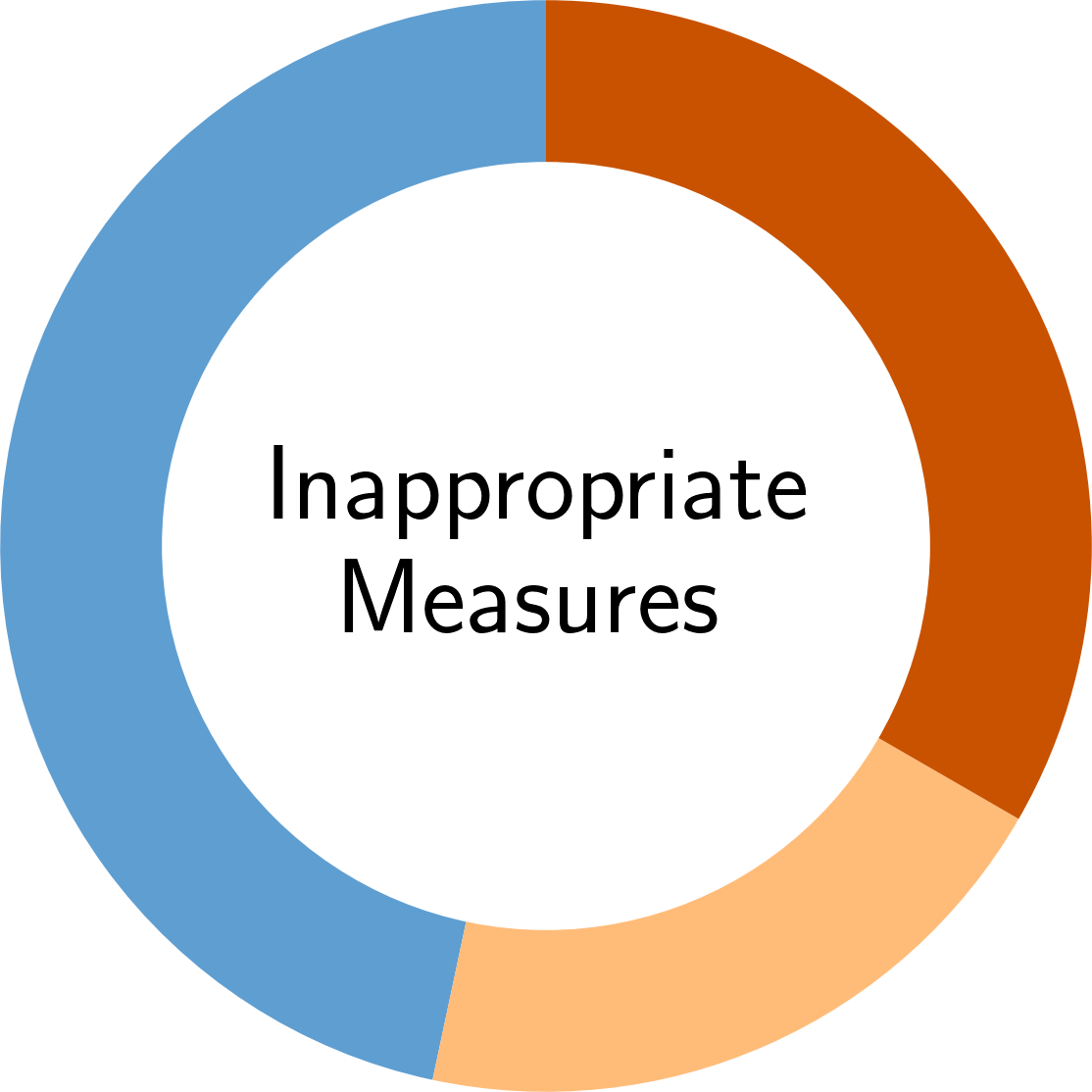


Paper
If you want to find out more about the identified pitfalls, you can read our publicly available paper. For interested readers, we also provide supplementary material:
Cite the Paper
To cite our paper, you can use the following BibTex entry:
@INPROCEEDINGS{ArpQuiPen+22,
author = {Daniel Arp and Erwin Quiring and Feargus Pendlebury and Alexander Warnecke and
Fabio Pierazzi and Christian Wressnegger and Lorenzo Cavallaro and Konrad Rieck},
title = {Dos and Don'ts of Machine Learning in Computer Security},
booktitle = {Proc. of USENIX Security Symposium},
year = {2022},
}
FAQ
In the following, we want to answer some questions you might have: